浅谈Volatile
浅谈Volatile关键字
在设计模式-单例模式 (yuewatch.com)一文中我们提到,普通的双检锁(不妨称其为双检锁V1.0)看似十分完美,但是在多线程环境中仍然可能存在线程安全问题。
// 双检锁V1.0
public class Singleton {
private static Singleton instance;
private Singleton() {}
public Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
以下是安全的双检锁V2.0,可以看到,仅仅是添加了一个volatile关键字。
// 双检锁V2.0
public class Singleton {
private static volatile Singleton instance;
private Singleton() {}
public Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
借由单例模式,我们引出对Volatile关键字的介绍。
在Java并发编程中,所有并发bug的源头即为三大特性:可见性、原子性、有序性。我们先来简单介绍一下这三个特性。
可见性
通俗来讲,可见性含义即为:当一个线程修改了线程共享变量的值,其他线程能够立刻得知这个修改。实际上,从性能的角度考虑,如果该变量在多次修改后才会被使用,那么在真正使用之前的多次同步都会造成性能的浪费。实际上,可见性的定义要弱一些,即只需要保证:当一个线程修改了线程共享变量的值,其它线程在使用前,能够得到最新的修改值。
实际上,这个问题会发生在任何具有缓存的系统中。如在硬件层面上,每个cpu核心拥有自己的l1、l2、l3等多级缓存,他们之间相互独立,并不可见。当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了,或者说,CPU-2上的缓存"失效"了。
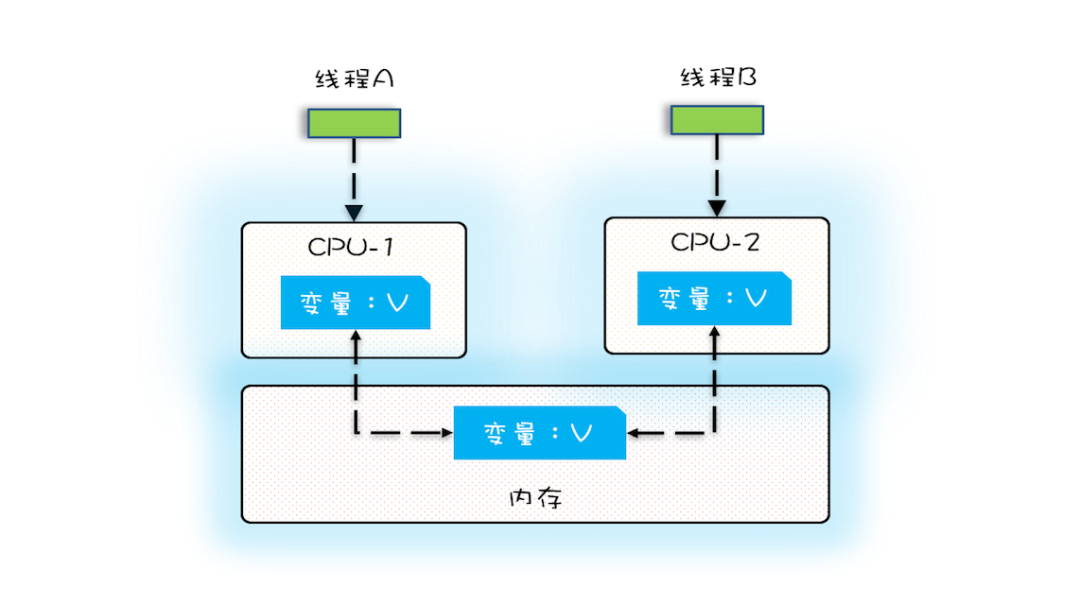
要解决这个问题很简单,只需要让CPU-1修改数据V后,让CPU-2在使用数据前,得知V已失效,从内存中获取最新修改的V的值即可。这就是MESI协议。这里不对该协议进行展开。
既然有了MESI协议,是否我们就无需使用Volatile关键字的呢?实际上并不是,我们提到,在任何具有缓存的系统中都可能发生问题,而MESI协议,仅仅解决了硬件层面的CPU缓存问题,而JVM内存模型也有自己的缓存机制,此时仅依靠MESI协议就无力解决了。
重排序
重排序问题大致可以分为两种:
- 真重排序:编译器、CPU等出于优化执行效率的目的将指令重新排序
- 假重排序:由于缓存同步顺序问题,看起来指令执行过程被重排序了(尽管它并没有被真正重排序)
在多线程环境中,由于线程之间共享可变数据,且重排序结果不固定,可能出现执行结果表现出随机性。
真重排序
真重排序其实就是通常认知上的重排序,即代码的实际执行顺序与我们自己写的不同。根据不同层次的重排序,又可以分为编译器层面的和处理器执行时的乱序执行。这里不做展开,只要知道,一切的一切都是为了执行效率最大化。
假重排序
真重排序的概念很好理解,那么所谓的假重排序又是什么意思呢?
假设程序顺序(program order)中先更新变量v1、再更新变量v2,不考虑真·重排序:
- Core0先更新缓存中的v1,再更新缓存中的v2(位于两个缓存行,这样淘汰缓存行时不会一起写回内存)。
- Core0读取v1(假设使用LRU协议淘汰缓存)。
- Core0的缓存满,将最远使用的v2写回内存。
- Core1的缓存中本来存有v1,现在将v2加载入缓存。
重排序是针对程序顺序而言的,如果指令执行顺序与程序顺序不同,就说明这段指令被重排序了。
尽管在cpu实际执行过程中,“更新v1”的时间早于“更新v2”时间的发生,但是Core1只看到了更新后的v2。此时,看起来似乎发生了指令重排,但实际没有重排。
可见,只要解决了可见性问题,假重排序问题自然就解决了。但并不能解决真重排序导致的问题。
原子性
在Java(包括其他高级语言)中,一条语句通常需要多条cpu指令完成。例如count += 1,看似简单的一条指令,其实我们可以将其拆分为三条指令(仅作为举例,实际情况可能并不是这样):
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
在执行完任意一条指令后都有可能发生cpu调度,从而执行其他线程。如果有两个线程同时操作count变量,则可能以如下顺序执行指令:
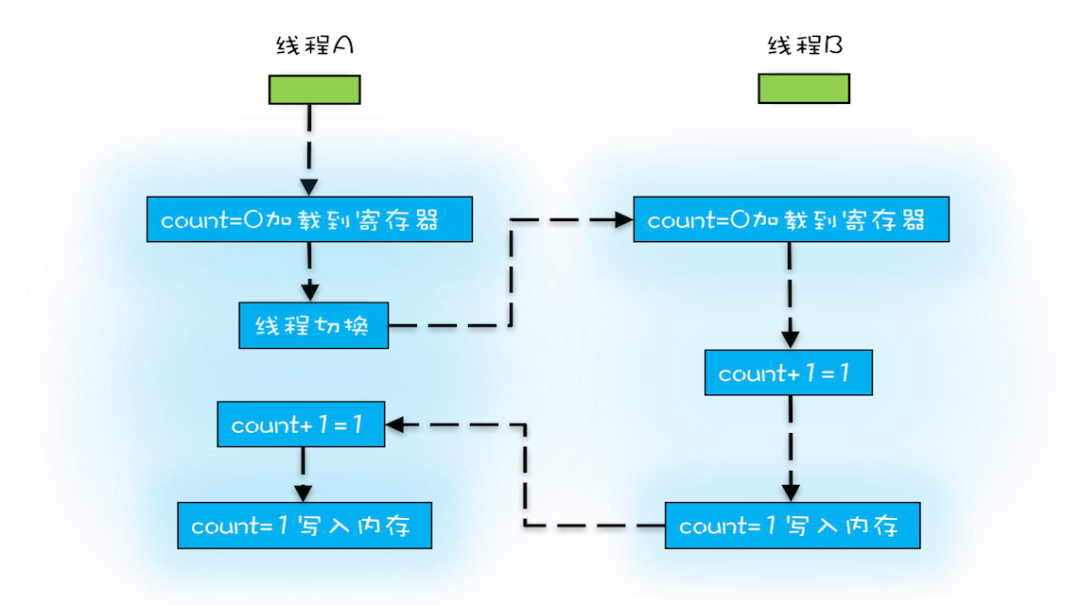
此时,就发生了写丢失问题,即本来应该被加两次1的count变量最终只被加了一次。
因此我们也可以给出原子性的定义:即指一个操作是不可被打断的,多线程环境下,操作不能被其他线程干扰。
Volatile关键字
volatile修饰的变量具有两个特性:
- 可见性:即,对一个volatile的读,总是能看到任意线程对这个volatile变量最后的写入。
- 有序性:volatile可以在一定程度上避免指令重排。
值得注意的是,volatile并不能保证原子性,这也是经常容易犯的错误。比如下面这串代码:
public class VolatileFearuresExample {
volatile long vl = 0L;
public void set(long l) {
vl = l;
}
public void getAndIncrement() {
vl++;
}
}
在介绍原子性的时候,我们就提到过++操作实际上是一个复合操作,一条语句的功能需要多条指令才能完成。而volatile是没办法保证其执行结果的正确性的。
另一种理解volatile的方式,是将上述代码变化为语义等价的下面这段代码:
public class SynchronizedFeaturesExample {
long vl = 0L;
public synchronized void set(long l) {
vl = l;
}
public synchronized long get() {
return vl;
}
public void getAndIncrement() {
long temp = get();
temp += 1L;
set(temp);
}
}
通过上述代码可以看到,volatile修饰的关键字在做单个变量的读写时可以保证原子性。但如果是多个volatile操作,或类似volatile++这类操作,没有办法保证操作整体的原子性。(实际上,这也是为什么有些地方称volatile可以保证原子性的原因)。
经过上述介绍,我们也可以很容易理解volatile的内存语义了,即:
- volatile写的内存语义:当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
- volatile读的内存语义:当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
这保证了volatile所修饰变量的可见性。但其仍然存在语义不清晰的问题。因此JSR-133对Volatile变量的相关语义进行增强,可以看如下代码:
public class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v) {
// 这里的x是多少?
}
}
}
线程A执行writer方法,按照volatile语义,会将变量v = true立刻刷新回内存。假设此时有B线程执行reader方法,并且看到了v = true,那么此时B看到的x的值是多少呢?
在JSR-133之前的旧的内存模型中,虽然禁止了volatile变量之间的重排序,但运行volatile变量与普通变量之间的重排序。在这个例子中,x与v之间并没有直接的数据依赖关系,所以可能导致线程B看到了新的v却看不见x。
而在新的内存模型中,volatile变量的语义被增强,现在如果volatile与普通变量之间的重排序可能破坏内存语义,那么,这种重排序就会被禁止。具体规则如下图:
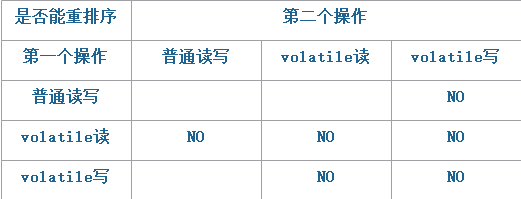
对该表的简单表述如下:对于Volatile变量禁止重排,这也是JSR-133以前的要求。JSR-133进一步增强Volatile语义,限制了普通变量读写与Volatile变量之间的重排规则。
内存屏障
在编译器层面,volatile作为一个标记,可以禁止编译器的某些重排序和禁用缓存,解决可见性问题(编译器重排)。而硬件层面的可见性和重排则通过在volatile变量读写的指令前后添加内存屏障实现(处理器重排)。
四种屏障类型如下:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作。它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
再谈双检锁
有了对Volatile关键字的初步理解,我们可以再来看看不加volatile修饰静态变量的关键字问题出在哪里。
让我们看看这一行代码:
instance = new Singleton();
看似一行代码,实际上,从对象创建的流程来看,可以被分为多个步骤:
- 构建对象,分配内存,并对所有成员变量赋默认初值
- 初始化对象,执行对象内部生成的init方法
- 将对象地址返回并赋值给变量
步骤二与三之间并无直接的依赖关系,因此在实际过程中可能发生重排。也就是在变量真正完成初始化前,对象地址先被赋值给了变量。此时,如果有另一个线程访问了getInstance方法,它将会拿到“半个对象”(被部分初始化的对象)。添加volatile关键字以后,对instance变量的Volatile写操作之前的所有读写指令都不能重排到其之后,保证创建并初始化对象先于赋值instance发生,避免其他线程获取未初始化对象的问题。
关于final
这里先鸽了,以后再说:)
参考链接:
{kind=link}
{kind=link}